Metinden görüntü üreten yapay zekalı araçlar, yeniliklere son derece açık olan yaratıcı dünya tarafından heyecanla karşılandı ama birçok soruyu da beraberinde getirdi. “Yapay zeka sanatçıları devre dışı mı bırakacak yoksa onlar için vazgeçilmez bir araç mı olacak? Yapay zeka, insanlığın gelmiş geçmiş tüm sanat mirasından çalıntılar yapan güçlü bir hırsız mı? Yapay zeka benim eserlerimi de çalıyor mu? ” Bu son sorunun cevabını ararken, “Sanat Hırsızlıktır” isimli şu animasyona da göz atmanızı tavsiye ederim. Şimdi bu hırsızlık konusuna dair yeni sorularla ve çözüm arayışlarıyla karşı karşıyayız. Bunlardan biri, sanatçı grubu Spawning tarafından yaratılan “Have I Been Trained”.
Introducing @spawning_ , building tools for artists to own and manage their AI training data ♥️
Artists can see if you feature in popular AI models at https://t.co/1Mh9vElQhA, and sign up to use our tools to opt-in or opt-out of AI training
I am here for questions, and excited! https://t.co/vHKtlZAgKz pic.twitter.com/OuuZJznB4q
— Holly Herndon (@hollyherndon) September 14, 2022
“Bir sanatçının çalışmaları, yapay zekayı besleyecekse sanatçının buna onay vermiş olması gerek”
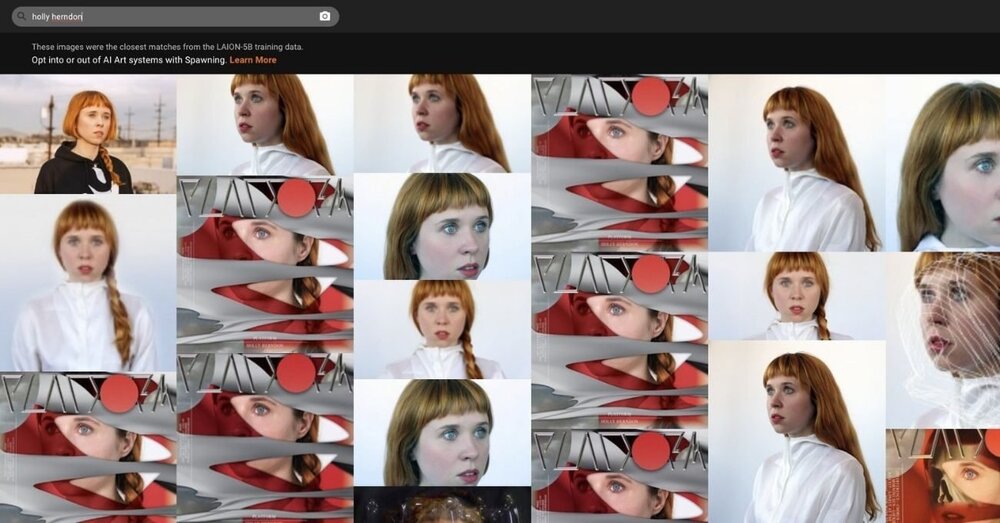
Have I Been Trained, sanatçıların çalışmalarının yapay zekalı görüntü oluşturucularını (ai art generator) eğitmek için kullanılıp kullanılmadığını öğrenmelerine olanak tanıyan bir internet sitesi. DALL-E, Midjourney, Google’ın Imagen’i ve Stable Diffusion gibi yapay zekalı görüntü oluşturucuları eğitmek için kullanılan görüntü sentezi modellerine yanıt olarak yaratılmış. Bu modelleri beslemek için kullanılan ve 5,85 milyar görüntüye sahip bir kitaplık olan LAION-5B eğitim veri setinde arama yapıyor.
Kullanıcılar, çalışmalarını bulabilecekleri anahtar kelimeleri kullanarak metin yoluyla arama yapabiliyor. Fotoğraf ya da görsel yükleyerek arama yapmak da mümkün.
“Yapay zekayı eğiten veri setleri, milyonlarca görselden izinsiz olarak besleniyor”
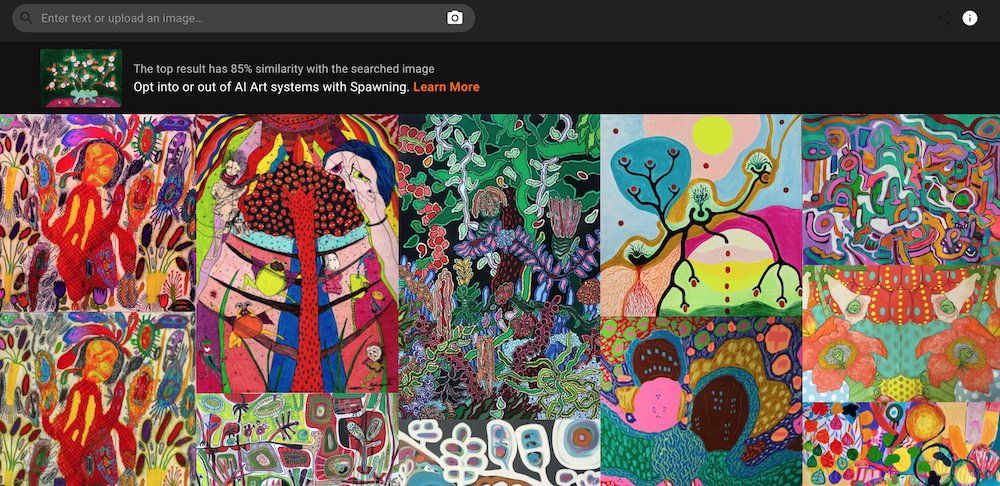
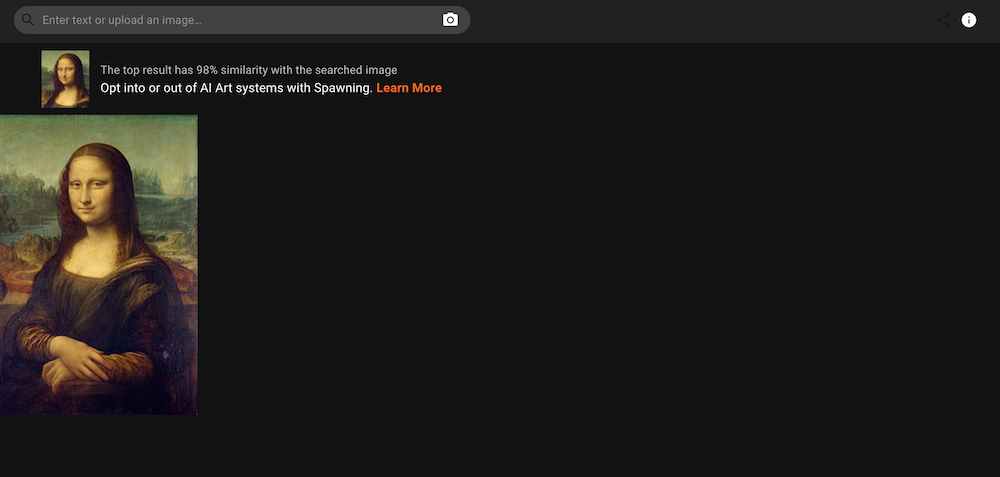
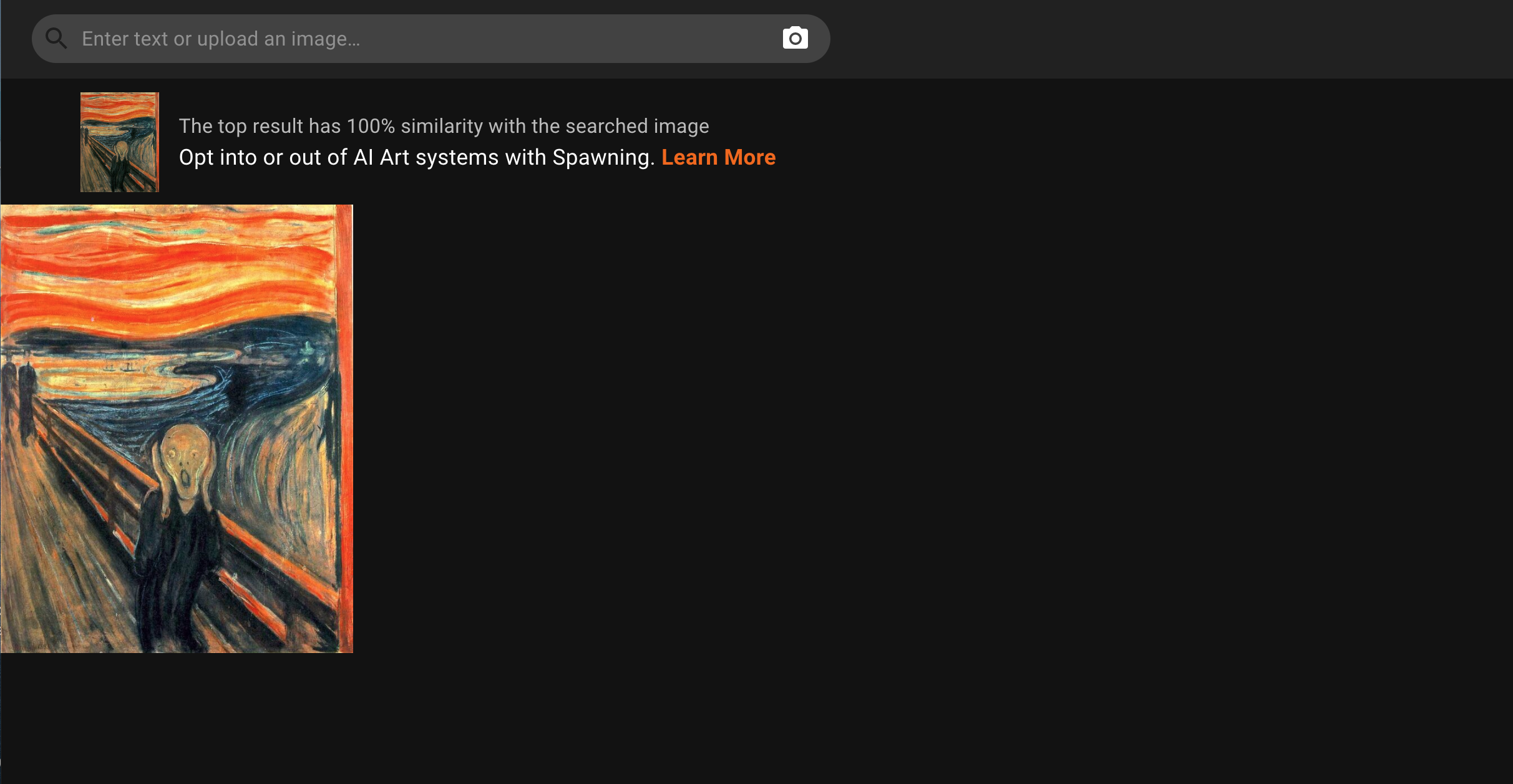
Bir arama motoruna benzeyen bu siteye, kendi çizimlerimden birinin fotoğrafını yüklediğimde onunla %85 benzerlik taşıyan görüntüler buldu ve listeledi. Yukarıda ekran görüntüsünü görebilirsiniz. Ancak bu arama sonuçları arasında benim çizimimin aynısı yoktu. Daha ziyade benim çizimimle yüksek oranda stil benzerlikleri taşıyan görseller vardı. Leonardo da Vinci’nin Mona Lisa tablosundan “bir kesit” yüklediğimde ise %98 benzerlik taşıyan bir görsel tespit etti ve LAION-5B tarafından kullanıldığını ortaya koydu. Benim yüklediğim Mona Lisa kesitinden daha büyük bir Mona Lisa görüntüsünü sonuçlarda tek başına sundu. Yine Edvard Munch’ın Çığlık isimli tablosunu tam boyutlu olarak arattığımda %100 benzerini tespit etti ve LAION-5B tarafından kullanıldığını ortaya koymuş oldu. Ekran görüntülerini aşağıda görebilirsiniz.
LAION-5B’yi oluşturmak için yapay zeka araştırmacıları tarafından yönetilen botlar; Getty Images, Flickr, Pinterest ve görsel havuzu niteliğindeki bunlara benzer milyarlarca internet sitesini tarıyor. Dolayısıyla LAION, telif hakkıyla korunan milyonlarca görselden izinsiz olarak besleniyor.
Spawning’in misyonu, eğitim verilerinde kullanılan eserlerde sanatçıların söz ve mülkiyet sahibi olabilmesi için araçlar oluşturmak. Eserlerin, büyük yapay zeka modellerinin eğitimlerinde kullanılması konusunda sanatçının söz sahibi olmasını sağlamak istiyorlar. Kullanıma izin vermek veya vermemek, stillerinin ve benzerliklerinin nasıl kullanıldığına dair izinler belirlemek ve dilerlerse kendi tercihleri doğrultusunda yapay zeka eğitiminde kullanılacak eserler sunmak. Bu son söylediğim sanatçılar için bir gelir modeli olabilir mi? Yoksa sanatçıların sırtından para kazanmak isteyen sosyal medya platformalarının gelir kaynağı mı olacak? Örneğin Instagram’ın üyelik sözleşmesinde, oraya yüklenen her eserin yapay zeka eğitimlerinde kullanılabileceğini de kabul edersek, kazanan bu platformlar olabilir. Bunları zamanla göreceğiz…
Spawning, ürettiği araçların her alandan sanatçılara faydalı olmasını hedefliyor. “İster görsel bir sanatçı, müzisyen, tasarımcı veya film yapımcısı olun, araçlarımızın sizin için faydalı olabileceğini düşünüyoruz. Her sanatçının, verilerinin nasıl kullanıldığı konusunda kendi kararlarını verecek araçlara sahip olması gerektiğine inanıyoruz.” Ayrıca endişelerinin endüstriyel ölçekte eğitim verilerinin kullanımı ile ilgili olduğunu söylüyorlar.
Görsel: Twitter






