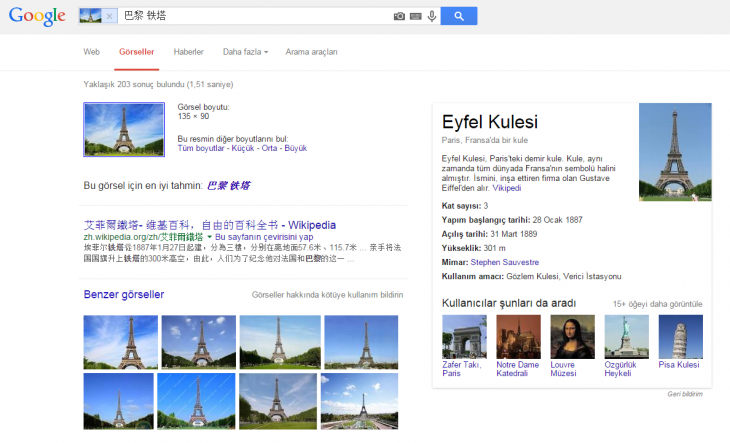
Google’ın her yıl düzenlediği yazılımcılara yönelik olan I/O etkinliğinde Google yöneticilerinden Vic Gundotra, sunumu sırasında Eyfel Kulesinin bir fotoğrafını gösterdi. Tüm katılımcılar fotoğrafın nereye ait olduğunu anladı. Tıpkı Google arama motoru gibi.
Mayıs 2013’te Google, Facebook, Yahoo ve birçok şirket bir araya gelerek bu teknoloji üzerindeki yatırımlarını arttırdı. İnternet üzerindeki sonsuz görseller, veri inceleme açısından balta girmemiş orman olarak tanımlanabilir. Görsel algılama algoritmaları; yüz, QR kodu, barkod, sanat eseri ve coğrafi şekiller ile başlayan bir yolculuğa sahip. Geliştirilen teknolojiler ise her görseli algılanabilir hale getiriyor.
Kuzey Karolina Üniveristesi Bilgisayar Bilimi bölümünde yayınlanan Object Recognition: History and Overview isimli makalede görsellerin algılanma sürecinde küçük ve kilit parçaların nasıl göz önüne alındığını anlatıyor. Perspektif ve açıya göre değişen sabit yapılar ile hareketli cisimler, ana hatlarıyla bütün olarak algılanmak yerine küçük parçalara ayrılıp farklı ihtimaller dahilinde tespit ediliyor. Bu sayede Eyfel Kulesinin önünde birisi olsa dahi beynimiz nasıl algılıyorsa bilgisayar da aynı şekilde algılıyor.
Görsel tanımlama işleminin bir diğer basamağı ise pikselleri RGB diye isimlendirilmiş renk kodlarına göre sınıflandırılması. İnsan gözünün algılayabildiği üç temel renk olan Red, Green, Blue yani Kırmızı, Yeşil, Mavi renklerin örnek pikseldeki renkte hangi oranlarda bulunduğunun algılanmasıyla görselin sayısal çizimi gerçekleşiyor. Böylece parçalanması ve sınıflandırılması kolaylaşıyor.
İnternet üzerindeki görsellerin bu temeller ile algılanarak tanımlanabilmesi pazarlama ve kurumsal açıdan da büyük önem taşıyor. Şu anki görsel tanımlama algoritmalarında bulunan hata payının sıfıra yaklaşmasıyla birlikte şirketlere yepyeni bir pazar açılmış olacak. Pinterest, Twitter, Facebook gibi ağlar ve bunları besleyen kaynaklar görsel algılama konusunda Google ve Yahoo ile birlikte projeye devam ediyor. Bu şirketlerin yüksek kıdemli temsilcilerinin ortak bir görüşü bulunuyor.
“Henüz markalar görsellerin altındaki altın madeninden ve potansiyelinden haberdar değil.”
Veri günümüzde her yerde her saniye bulunabiliyor. Sonsuz bir akış içerisindeki bu veriyi bulmak kadar onu anlamak ve değerlendirmek de kilit hamleler arasında yatıyor. Sadece veriyi elde etmek değil onun nasıl verimli kullanılabileceğini öngörmek de gerekiyor.
Shazam, ismini bilmeden dinlediğiniz bir müziği dinlettiğiniz ve size parça bilgisi ileten bir mobil uygulama. Bu açıdan bakıldığında her şey çok sade ve kullanışlı. Fakat Shazam bunu nasıl yapıyor? Dinlettiğiniz parçayı küçük parçalara bölerek internet üzerinde arama yapıyor. Bu parçaları anlamlı bir sıraya koyarak doğru eşleşmeyi buluyor size sunuyor. Yani herhangi bir işlem yapmadan uygulama kendi kendine veriyi buluyor, analiz ediyor ve size kullanabileceğiniz haliyle sunuyor.
Her gün kişisel bir işlem yapmak için belirli kutulara şifre giriliyor. Eğer şifre yanlış girilirse veya bir güvenlik protokolü daha bulunursa recaptcha teknolojisiyle rastgele gösterilen sayı ve kelimeleri yazarak insan olduğumuzu ispatlıyoruz. Sistem çok basit, beş saniye içinde doğru kombinasyonu yazarak geçiyoruz. Peki ya bu işlemi ile basılı kitapların dijital kopyalarını çıkarabilir miyiz? Yanıt, evet. Luis von Ahn, TEDxCMU’da yaptığı konuşmada geliştirdiği yabancı dil öğrenme internet sitesi Duolingo ile birlikte önceki projesi recaptcha’nın arkasındaki mekaniği anlatıyor. Dijital taramalar sonucunda kitaplarda okunamayan veya hataları kelimeleri algoritma bize gösteriyor. Ve bilgisayarın okuyamadığı kelimeleri, insan olduğumuzu ispatlarken bilgisayar için çevirmiş oluyoruz.
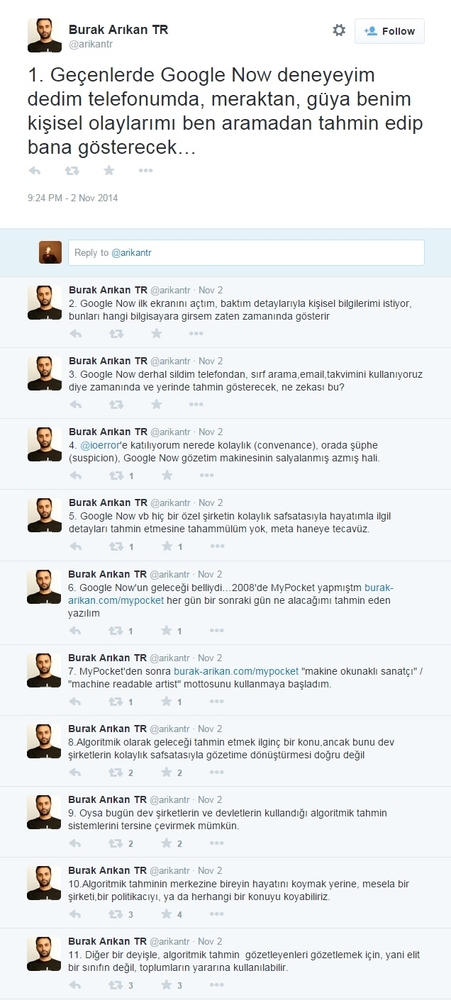
Diğer yandan, sanatçı Burak Arıkan’ın, Android ana ekran uygulaması olan Google Now ve Google Now’ın en büyük iddiası olan kişisel gelişmeleri tahmin etme yeteneği hakkındaki Twitter hesabı üzerinden paylaştığı görüşlerini de dikkate almak gerekiyor. Verinin toplanma ve incelenme süreci son kullanıcıdan basit işlemler yapmasını istiyor. Fakat bu işlemler, büyük resimde önemli değişikliklere neden oluyor.
Bu örnekler ile birlikte internet üzerinde bulunan ve her saniye kopyalanmaya, üretilmeye devam eden görsel içerikleri algılayan bir algoritma hem son kullanıcının hem de markaların pazarlama tekniklerini değiştirmekte ne kadar rol oynayabilir?
Balta girmemiş ormana benzerek açıklanmamızın sebebi de tam olarak bu. Sonsuz görsel havuzundaki veriyi topladıktan sonra kullanılabilir ve işlenebilir hale getirildiğinde yepyeni bir veri, dünya ve pazarlama algısına kavuşacağız.
Görsel; Flickr, Google






