
2016 yılında zamanı donduran akım olarak ortaya çıkan ve kısa sürede sosyal medyada pek çok kişi tarafından Mannequin Challenge aradan geçen süre zarfında popülerliğini yitirdi. Artık sosyal medyada daha farklı akımlar bulunuyor. Ancak Google AI (yapay zeka) araştırmacıları Mannequin Challenge’ı derinlik tahmin algoritmasını (depth prediction algorithm) geliştirmek için kullanmaya devam ediyor.
Meydan okuma temelinde bir grup insansın hareketsiz bir şekilde poz vermesini hedef alıyor. Kamera sabit duran insanların etrafında dönüp onların hareketsizliğini çekerken aslında bir yandan da alan derinliğini algılamaya yardımcı olacak veri oluşturuyor.

Mannequin Challenge sayesinde yapay veri yaratmaya gerek kalmıyor
“Learning the Depths of Moving People by Watching Frozen People” başlıklı Nisan ayında makalede belirtildiği üzere derinlik tahminini sağlamak için görüntüde yer alan statik alanlar kullanılıyor. Temelde cansız manken taklidini içeren bu veri kaynağı sayesinde derinlik çıkarılıyor ve 3B efektler ile gösterilebiliyor. Google araştırmacıları da derinlik haritalarını ve derinlik tahmini modelini oluşturmak için doğal olmayan bir veriden faydalanmak yerinde YouTube’da yer alan 2 binin üzerindeki Mannequin Challenge videolarından faydalanıyor.
Bu akım olmasaydı insanların doğal eylemlerinin gerçekçi bir şekilde modellenmesi ve oluşturulması için yapay veriler kullanılacaktı. Yapay veriler üzerinden eğitilmiş model gerçek sahnelerin haritalamasını çıkarırken zorlanacaktı. Tüm modellerin sabit olduğu ve sadece kameranın hareket ettiği bu akım sayesinde multi-view-stereo (MVS) gibi yöntemler kullanılarak içinde insanların da olduğu sahnelerin derinlik haritaları elde edilebiliyor.
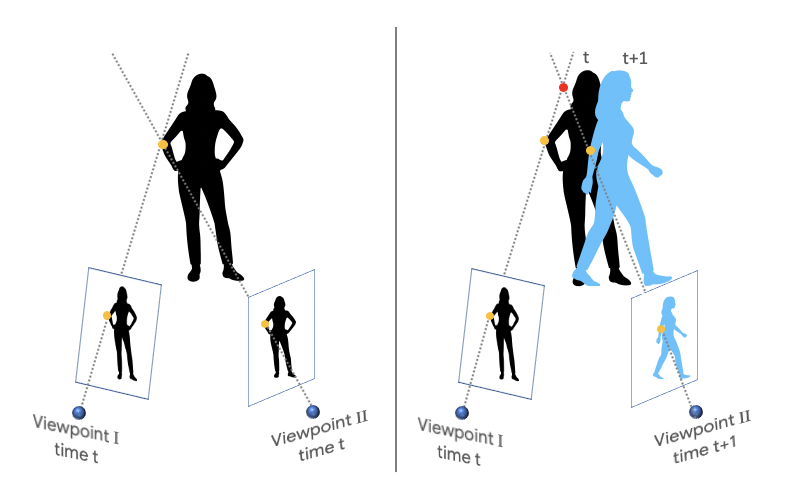
Hareketli insanların olduğu videolarda derinlik nasıl hesaplanıyor?
Derinlik tahmini için tek görüntü üzerinden yöntemler geliştirilmiş durumda. Araştırmacılar birden fazla kareden gelen bilgileri dikkate alarak sonuçları daha verimli hale getirebileceklerini söylüyor. Örneğin iki farklı bakış açısı arasındaki statik nesnelerin değişen konumu derinlik ipuçları sağlıyor. Bu tür bilgilerden faydalanmak için iki kare arasındaki 2B optik akışı hesaplanıyor. Bu akış hem sahnenin derinliğine hem de kameranın göreceli konumuna bağlı. Ancak kameranın konumu bilindiği için denklem dışında kalabiliyor. Böylelikle derinlik haritasına ulaşılıyor.


Hareketli insanların olduğu derinlik haritası testlerinde ise başlangıçta insan bölgeleri maskelenerek bir insan segmentasyon ağı uygulanıyor. Ağ sayesinde insanın olduğu bölgelerdeki derinlik hesaplaması başka alanlardan alınan verilerle oluşturuluyor. İnsanın hareket ettiği alanın arkasında kalan bölge videonun diğer karelerinden alınan piksellerle dolduruluyor. İnsanların belirgin şekilleri sayesinde ağ birçok eğitim modelini gözlemleyerek öğrenebiliyor ve gelişiyor.
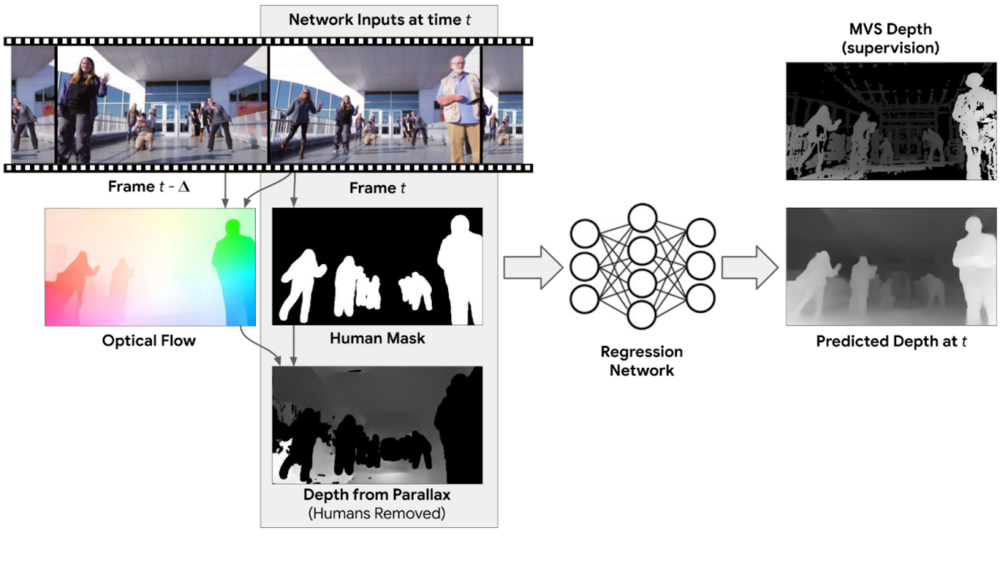
Bilim insani Tali Dekel ve mühendis Forrester Cole, Mayıs ayında Google AI Blog’da yayınlanan yazıda makine öğrenmenin (machine learning) son zamanlarda derinlik tahmini çalışmalarında kullanıldığını ancak öğrenme tabanlı bir yaklaşımı deneyen ilk çalışmanın bu olduğunu söylüyor. Geliştiriciler el kameraları ve 3B video ile çekilen sahnelerin artırılmış gerçeklik deneyimlerini oluşturmada yardımcı olabileceğini belirtiyor.
Görsel: YouTube, Google AI






